
论文题目:NetGPT: Generative Pretrained Transformer for Network Traffic
论文作者:Xuying Meng, Chungang Lin, Yequan Wang, Yujun Zhang
发表会议/期刊:arXiv
发布时间:2023
主题类型:流量分析
笔记作者:JSY@Web 攻击检测与追踪课程
作者主页:孟绪颖 http://www.ict.ac.cn/sourcedb/cn/jssrck/202012/t20201204_5808220.html
研究概述
NetGPT 是一种生成式预训练 Transformer 模型,旨在解决现有的传统网络流量模型仅为解决特定任务设计、难以在小样本数据集上充分训练、开发成本高昂的问题。NetGPT 通过预训练策略,利用大规模的网络流量数据学习其内在特征,使其能够轻松适应各种下游任务,如应用分类、攻击检测和流量生成。
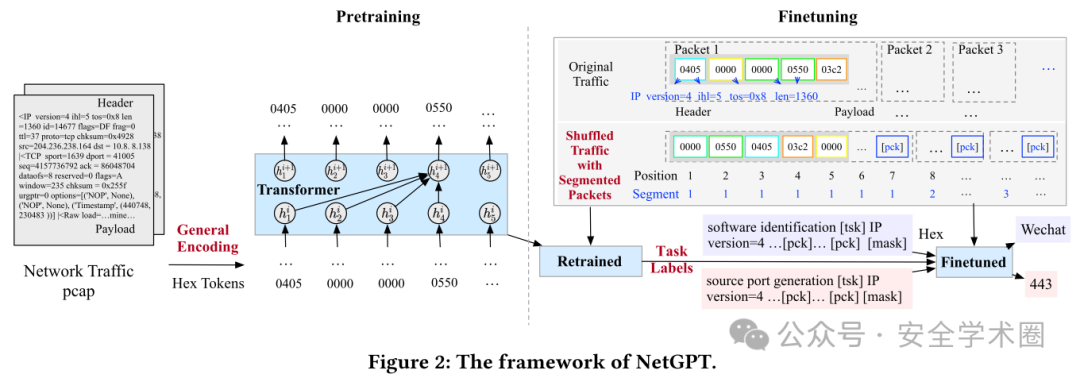
在技术实现上,NetGPT 引入了多模式网络流量建模,通过将异构的网络流量头部和载荷编码为统一的文本输入,支持流量理解和生成任务。在预训练过程中,NetGPT 使用基于十六进制的通用编码策略,将明文和加密流量转化为通用语义空间,从而构建了一个基础的预训练模型。在微调过程中,通过随机化头部字段、分割流中的数据包,并结合任务特定标签来优化模型,以适应不同的下游任务。
实验结果表明,NetGPT 在多种不同的流量数据集上的流量感知和流量生成任务均表现出色,显著优于当前最先进的基线模型。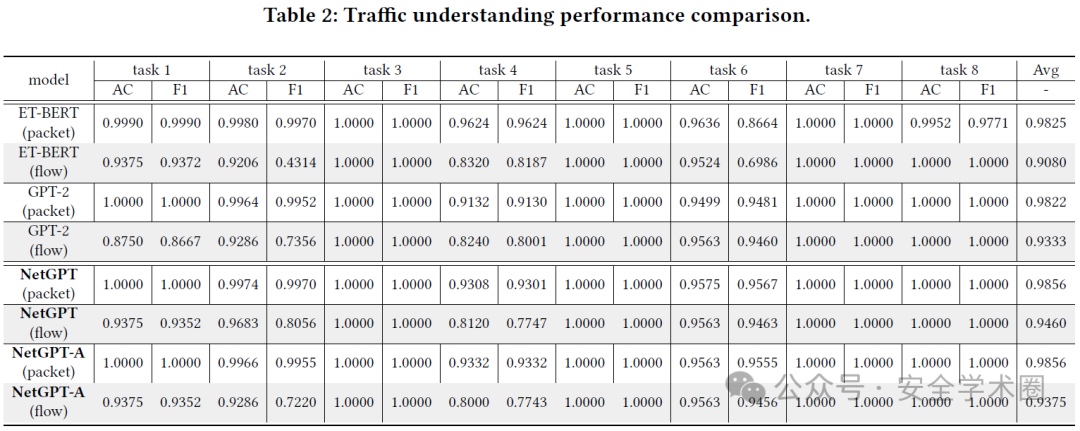

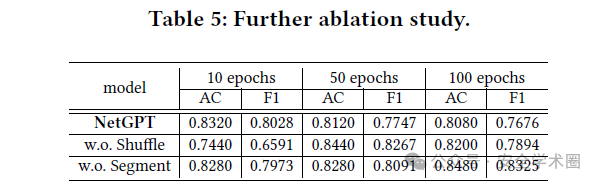
作者进一步做了消融实验,检测移除随机化头部字段和数据包分割模块的影响,进一步证明所提出方法的有效性。

贡献分析
贡献点1:文章提出了一个通用的、可以在包层面和流层面均实现流量感知和流量生成的预训练模型框架:NetGPT; 贡献点2:文章提供了一种可以统一不同种、不同长度的网络流量输入的编码生成方案,从而实现多模式的网络流量建模; 贡献点3:文章针对不同网络任务对上下文依赖的不同需求,提出了通过随机化头部字段和分割数据包来优化预训练模型的适应性的方法,实现了对多种下游任务的支持。
论文点评
优点
提出了一种通用的编码方案,使模型具有较强的通用性和广泛的任务支持性; 在数据处理过程中加入随机化头部字段和数据包分割,有助于缓解小样本问题,保留了数据包的语义和顺序信息; 任务针对了包和流两个层次; 实验详实,工作量足。 可改进之处
过拟合问题:虽然NetGPT已经展示了优秀的性能,但其在预训练和微调的过程中加入的操作也引入了过拟合的风险。加密流量种类复杂,在数据量有限的情况下较易产生过拟合的问题; 实际应用的问题:由于模型基于较复杂的预训练模型(BERT-base已经有几百M的大小),在主流配置和网络流量强度下,在线实时检测或是旁路镜像检测镜像检测的速度均无法满足要求。
论文文献
[1] Meng X, Lin C, Wang Y, et al. Netgpt: Generative pretrained transformer for network traffic[J]. arXiv preprint arXiv:2304.09513, 2023.
https://arxiv.org/pdf/2304.09513
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com