
论文题目:DeepCoFFEA: Improved Flow Correlation Attacks on Tor via Metric Learning and Amplification
论文作者:Se Eun Oh; Taiji Yang; Nate Mathews; James K Holland; Mohammad Saidur Rahman; Nicholas Hopper;
发表会议/期刊:IEEE Symposium on Security and Privacy
发布时间:2022
主题类型:追踪分析
笔记作者:XYX@Web攻击检测与追踪课程
第一作者/通信作者主页:https://www.ewha.ac.kr/ewhaen/professor/info.do?mode=view&pId=h1bArTGq%2FKLIZlajLCRPzA%3D%3D

研究概述
端到端流相关攻击是针对低延迟匿名网络的攻击,是Tor流量分析的常用手段。最近的研究表明,单个流可以以高精度进行关联,但即使是最先进的攻击,其计算成本也很高:流的成对性质,需要在对流之间进行比较,以对个用户进行匿名化。计算需求的组合爆炸和基本速率的逐渐下降,导致了大量的假阳性或极小的成功相关率。本文介绍了一种新的流相关攻击DeepCoFFEA。首先,使用深度学习来训练一对特征嵌入网络。这些网络分别将Tor和出口流映射到一个相关流相似的低维空间;嵌入流对的成本比完整迹线更低。接着,使用放大将流划分为短窗口,并在这些窗口中使用投票来显著减少误报;相同的嵌入网络可以增加数量的窗口,以独立地降低假阳性率。
如图展示了DeepCoFFEA模型的架构,该模型由两个FEN模型和一个分类器组成。FEN模型能够提取有用的特征。第一个FEN模型A网络将输入的Tor流量映射到特征嵌入向量中,第一个FEN模型P/N网络将输入的出口流量映射到特征嵌入向量中。每个FEN模型由四个1D卷积块组成,包括两个1D卷积层和一个最大池化层,之后还使用了全局平均池化层来减少参数数量,并使用Dropout技术来防止过拟合。在两个FEN模型之后,作者使用了一个分类器对生成的特征进行分类和识别。该分类器由三个全连接层组成,其中第二个全连接层包含三元组损失函数,用于训练DeepCoFFEA模型。
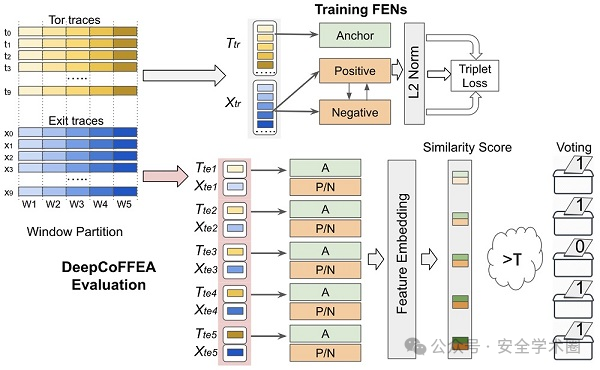
本文进行了实验分析,表明DeepCoFFEA显著优于Tor上的最先进流相关攻击,例如,93%的真实阳性率,而当调整为高精度时,最高为13%,比之前的工作提高了两个数量级。
贡献分析
贡献点1:论文针对客户端和入口中继之间的流量与出口中继和目标服务器之间的流量不同的问题,提出了对每对流进行多个独立部分的相关性测试的方法,将流划分为一系列k个短时间段或窗口,然后提取每个流的k个嵌入,并对Tor流和出口流进行逐步成对比较,正确匹配的流应该在所有k个窗口中关联。实现了增大真阳性(TP)和潜在假阳性(FP)之间的差异; 贡献点2:论文针对计算两个流向量之间的相关性成本较高的问题,提出了优化的三元组网络方法,将Tor流和出口流嵌入低维空间进行相似度计算,实现了对成本的显著降低。
代码分析
代码链接https://github.com/traffic-analysis/deepcoffea
代码使用Tensorflow、Numpy、Matplotlib实现,全部为开源类库。 代码实现共分为4个模块,分别为数据筛选(filter.py)、模型构建(new_model.py)、模型训练(train_fens.py)、结果评估(eval_dcf.py)。模型实现基于已有的开源函数库主要工作量为: 主要功能1:构造了一个基于深度学习的特征嵌入网络,分别将Tor和出口流映射到一个相关流相似的低维空间,进行相似度计算;[ train_fens.py:def load_whole_seq_new(tor_seq,exit_seq,circuit_labels,test_c,train_c,model_gb):]主要功能2:将流划分为短窗口,并在这些窗口中使用投票来显著减少误报,同时相同的嵌入网络可以增加数量的窗口,以独立地降低假阳性率。[ new_model.py:def create_model(input_shape=None,emb_size=None,model_name='')]
论文点评
DeepCoFFEA 将三元组网络架构调整为特征提取器,低成本实现完整的流量对比较。此外,通过将流分成少量窗口,为每个窗口提取特征,创建了多个半独立的相关性测试,这些测试可以组合起来以放大匹配流对和不匹配流对之间的差异,从而降低误报率。但仍然有部分值得继续探究的地方:
数据集依赖性:作者使用了两个数据集,DeepCorr数据集和他们自己收集的DCF数据集。DeepCorr数据集包含了12,503个流量对,而DCF数据集则包含了60,084个独特的网站流量对。作者并未严谨介绍自己收集数据的方法,同时他也表示真实的Tor流量数据可能会面临更低的想关性,因此本文的实验结果会有较强的数据集依赖性,尽可能收集不同Tor网络的流量数据进行实验是必须的。
模型泛化能力:虽然DeepCoFFEA在实验中表现出了跨不同目的地、时间的可转移性,但其在面对未知或未见过的流量模式时的泛化能力仍然是一个开放的问题。
对现有防御的评估:作者测试了DeepCorr和DeepCoFFEA对抗Obfs4、WTF-PAD和FRONT等防御措施的有效性。但并未说明随着防御策略的改进,相应的流量关联方法能否继续生效,或者同步进行更新。这种对未来的流量数据的特征进行自学习等处理的需求,是现在很多研究缺少的。同时,作者的研究也并未考虑到如果流量在Tor网络中进行了水印清除等操作后,会不会对实际的关联效果产生影响,及并未验证方法的鲁棒性。
通过这篇文章,我们可以看到流量关联这一领域目前正在尝试深度学习技术来进行实践,并在实时性、准确性等方面有了较大的进展,但面对真实的匿名网络,模型可以发挥的效能依旧不够稳定,同时方法的鲁棒性等方面也有更多需要考虑的地方。作者提出可以尝试更复杂的DNN架构来减小训练集的大小,以及通过研究抵御基于DNN的流量分析攻击的防御措施,尝试进行对抗生成实验,促进流量关联技术的进步。
论文文献
Oh S E, Yang T, Mathews N, et al. DeepCoFFEA: Improved flow correlation attacks on Tor via metric learning and amplification[C]//2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022: 1915-1932.
https://www-users.cse.umn.edu/~hoppernj/deepcoffea.pdf
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com