1
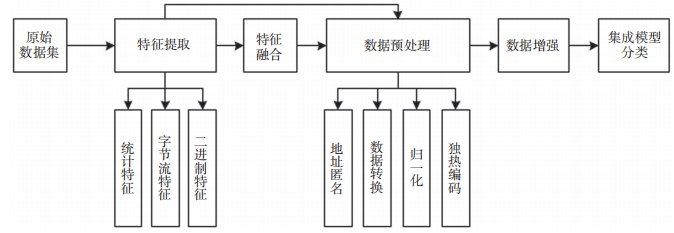
网络流量特征
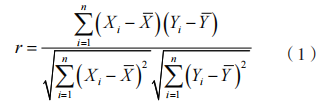
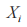 为变量 X 的第 i 个观察值;
为变量 X 的第 i 个观察值;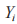 为变量 Y 的第 i 个观察值;
为变量 Y 的第 i 个观察值;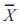 为变量 X 的平均值;
为变量 X 的平均值;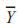 为变量 Y 的平均值,且相关系数介于 -1 和 1 之间。
为变量 Y 的平均值,且相关系数介于 -1 和 1 之间。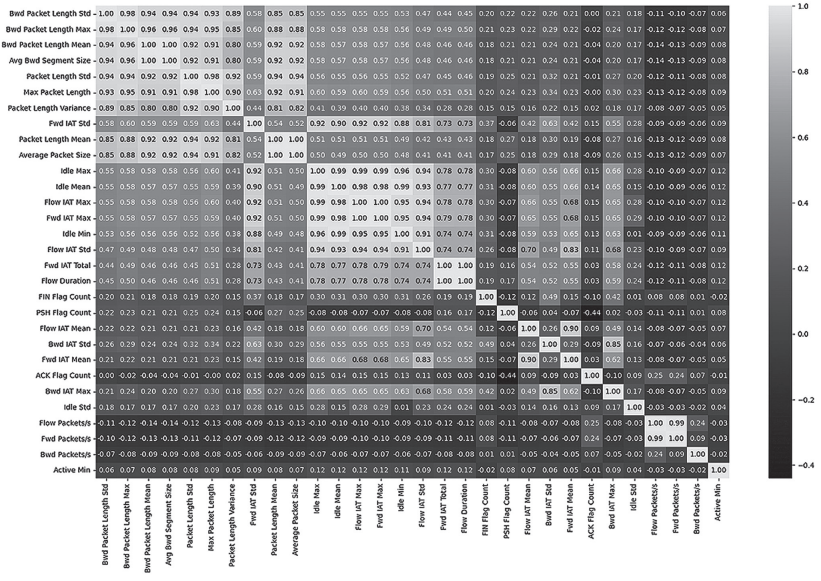
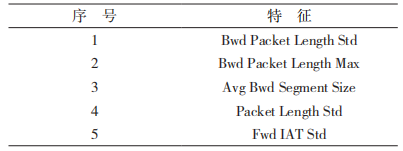

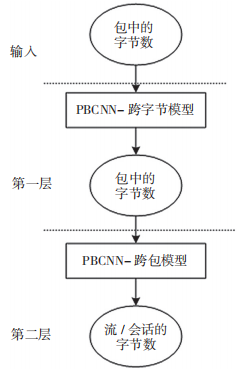
2
数据增强和集成学习
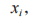 生成合成样本
生成合成样本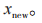

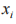 之间的位置。
之间的位置。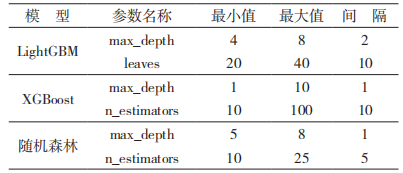
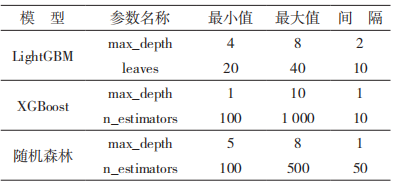
3
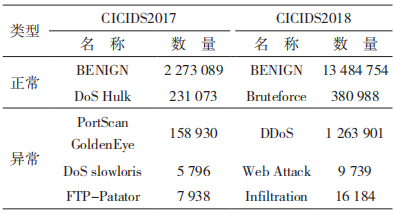
实验和结果分析
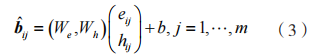
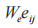 为字节特征表示,
为字节特征表示,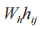 为字段特征,采用一种全局混合池化方法,该方法结合了全局平均池化和全局最大池化,能够提取数据包负载长度的特征和负载内容的特征,具体过程为:
为字段特征,采用一种全局混合池化方法,该方法结合了全局平均池化和全局最大池化,能够提取数据包负载长度的特征和负载内容的特征,具体过程为: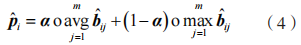
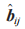 表明位置ij 的字节分布情况和字段的存在情况;向量
表明位置ij 的字节分布情况和字段的存在情况;向量 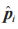 表示提取的数据包特征。
表示提取的数据包特征。

 和输出 y 之间的差异最小化。
和输出 y 之间的差异最小化。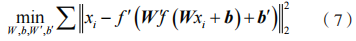

4
结 语
引用格式:吴苏亚 , 丁要军 . 基于集成学习的多特征网络流量检测 [J]. 通信技术 ,2024,57(7):731-738.
吴苏亚,男,硕士研究生,主要研究方向为网络安全、机器学习、网络流量分类;
丁要军,男,博士,教授,主要研究方向为网络安全、机器学习、网络协议识别
编辑:陈十九
审核:商密君
征文启事





